PortSwigger: All Directory Traversal Labs

In this post, I will cover all of the Directory Traversal labs located at PortSwigger Academy as well as providing some context regarding what it is and the vulnerabilities associated with it.

Directory Traversal
What is directory traversal? Well, it allows an attacker to read arbitrary files on the server that is running an application. It might include application code/data, credentials, or sensitive OS files like passwd and shadow.
In some cases, an attacker can write arbitrary files onto the server, allowing them to modify application data and take full control of the server - insanely bad, but insanely good for us.
Sometimes you see something like this in the URL:

The value "uploads/IMG0624.JPG" looks like a filesystem path - the "/" gives it away that it is probably Linux. It's similiar to browsing files on your computer when changing the image name from IMG0624 to IMG0625 - the chances are you are going to see another image file in the same directory and the parameter that specifies the system path in this case is called "file".
As an example, here is another:

Judging from the /, we can assume the server is running on Linux. To get to the beginning of the system, you can use a series of dot-dot-slashes (../../../../../). This essentially goes up in directories as far as it can.
It's generally a good idea to URL encode your web application payloads. For example::
http://example.com/test?file=..%2F..%2F..%2Fsomefile
Exploiting Directory Traversal
As another example, consider a shopping site that displays images of items for sale and these images are loaded using HTML <img> tags.
<img src="/loadImage?filename=218.png">
The loadImage URL takes a parameter called “filename” and returns the contents of the specified file. The image files themselves are likely stored on disk somewhere. In terms of Linux, a common directory for web hosted files is /var/www and may include a /images subfolder.
To return this image, the app would append the requested filename to the base directory and use a filesystem API to read the contents of said file. In the above, the full path would be:
/var/www/images/218.png
A bad website would implement no defenses against an attack against this, so an attacker could request the following URL to retrieve an arbitrary file from the server’s filesystem such as /etc/passwd:
https://insecure-website.com/loadImage?filename=../../../etc/passwd
Which, in turn, would cause the application to read the following file:
/var/www/images/../../../etc/passwd
The ../ sequence is a valid file path and would step us up one directory. Going up three directories, it would then read /etc/passwd.
On Windows, both ../ and ..\ are valid directory traversal sequences, and an equivalent attack to retrieve a standard OS file would be:
https://insecure-website.com/loadImage?filename=..\..\..\windows\win.ini
Many applications that place user input into file paths implement some kind of defense against path traversal attacks, and these can often be circumvented. If an application strips or blocks directory traversal sequences from the filename, it might be possible to bypass the defense.
One example is you might be able to use an absolute path from the filesystem root, such as filename=/etc/passwd to directly reference a file without using any traversal techniques.
If that does not work, the application might be filtering out the “../” sequence, but only filtering it out one time. In that case, you can use nested traversal sequences such as ….// or ….\/, which revert to ../ when the filter is applied.
In some contexts, such as in a URL path or a filename parameter of a multipart/form-data request, web servers may strip any sequences before passing input to the backend. It may be possible to bypass this sanitization by single/double URL encoding or another to encode the ../ characters, resulting in %2e%2e%2f or %252e%252e%252f.
Non-standard encodings as well such as %c0%af or %ef%bc%8f may also work.
If an application requires that the user-supplied filename MUST start with the expected base folder, such as /var/www/images, then it may be possible to include the required base folder followed by ../:
filename=/var/www/images/../../../../etc/passwd
If an application requires that the user-supplied filename must end with an expected file extension, such as .png, then it might be possible to use a null byte to effectively terminate the file path before the extension is added.
filename=../../../etc/passwd%00.png
A null byte represents the string termination point or delimiter character which means to stop processing the string immediately. Bytes following the delimiter will be ignored. In short, it basically means anything after it gets ignore (think of it like commenting out the rest of the input/string).
Prevention
The most effective way to prevent file path traversal is to avoid passing user-supplied input to filesystem APIs. Many app functions that do this can be rewritten to deliver the same behaviour in a safer way. If it is considered unavoidable to pass user-supplied input to filesystem APIs, then two layers of defense should be used together to prevent attacks:
The app should validate the user input before processing. The validation should compare against a whitelist of permitted values. If that is not possible, then the validation should verify that the input contains only permitted content, such as purely alphanumeric characters.
After validating the supplied input, the app should append the input to the base directory and use a platform filesystem API to canonicalize the path. It should verify that the canonicalized path starts with the expected base directory.
This covers the basics and should be enough to do the apprentice level labs. However, isn’t it more fun to delve even deeper to impress that interviewer in your dream job? If you think so, then read the next section :)

Deep Dive into Directory Traversal
As with the SQL Injection lab, are you ready for a deep dive conversation into directory traversal now that you have the basics covered? Yes? Then let’s go!
So, what is directory traversal? Well, it’s a vulnerability that allows a malicious actor to read files on the server that is running the application.
As an example, imagine we have an app that allows you to view cat images. The way the application works is that when you visit a certain image in the app, it makes a GET request to the back end server that takes in the file name of the cat image you want, the backend processes it, retrieves the file and then displays it back to you.

The issue is that if the filename is user controllable (i.e. coming from the client side) and it is not validated by the back end, then you could view any file on the system you want, not just cute cat images. For example, instead of cat.jpg, you could request the /etc/passwd file on a Linux system:

Passwd is world readable file accessible by anyone on the system including the app itself. When you make this request, the application retrieves the content of that file and displays it back to us in the application.
These types of vulnerabilities are EXTREMELY simple to exploit once you find it. Continuing on, let’s look at an example of how this vulnerability is introduced into code. Take the following PHP code for example:

It’s estimated that the root cause of 90% of web app vulnerabilities is that the application does not properly validate user input. What does that mean? It means having no or inadequate defenses in place that ensure that the input coming from client-side is not malicious.
Above, we have vulnerable code. On line 2, we initialize a variable called template and set it to the value blue.php. Then, we have an if statement that asks if the cookie TEMPLATE is set - i.e. does it exist/is it empty?. If it is not empty, we set the value of the cookie TEMPLATE to the variable $template that we just initialized. On line 5, we use the include statement to include and evaluate the file path /home/users/phpguru/templates/ and then append the value of whatever the $template variable is.
The issue is that the variable $template is user controllable (coming from client side) and it not validated in any way in the backend.
As an attacker, we could exploit this vulnerability using the following request:

The TEMPLATE cookie is coming from the client side. We simply add a directory traversal payload to exploit the vulnerability. The above payload is a very common payload for traversal vulnerabilities. It moves up many directories until we reach the root directory (/) and then we call the passwd file which exists in the /etc directory.
What happens when the application receives this is that it goes to the piece of code responsible for this request (line 4), sets the content of the variable $template to the value of the cookie TEMPLATE (our payload). Finally, it appends it to the /home/users/phpguru/templates/ path. Once appended, the “../” - traversal sequence - escapes us from the directory until we hit the root (/).
Finally, at the end, all it has to evaluate is the /etc/passwd file and then displays the contents of that file for us.
It’s important to mention that we pick the /etc/passwd file because it is world readable - regardless of the privileges the app is running with, we can view the content of that file. If the app was running with root privileges, we could exploit the vulnerability to view even more sensitive file like /etc/shadow that stores the hashes of local users on the system.
Impact of Directory Traversal
With regards to the CIA Triad (Confidentiality, Integrity, Availability), we can discuss the impact that directory traversal has on each of these points.
In terms of Confidentiality, this is usually impacted because it allows you to access and read files on the server. However, it is not that clear when it comes to the other two.
Some directory traversal vulnerabilities allow you to call programs that have the ability to execute commands. With this, you could use the directory traversal vulnerability to run commands and therefore, in a sense, for integrity, you are able to alter files on the system and for availability, you are able to delete files on the system.
The idea is that in that scenario, you technically have full RCE on the server, as if you can execute commands, then you could just upload a shell and RCE the server. In that case, confidentiality, integrity and availability would all be set to high and the directory traversal vulnerability would end up rating at critical.
How Common and How Critical Is It?
One way to measure this is the OWASP Top 10 list. The OWASP Top 10 is a list of the top 10 most critical security risks facing web apps that is updated every couple of years:

Directory traversal does not have its own category, but it does fall under the overall category called “Injection” which is considered the third most critical security risk facing web apps in 2021.
How to Find Directory Traversal Vulnerabilities?
How do you test if an application is vulnerable? Depending on the type of test, there are different methods. The two types are:
Black-box testing - tester is given little to no information about the system apart from the URL and scope of the engagement
White-box testing - tester is given complete access to the system including source code
There is a third category called grey-box, which is a combination of both - given limited information and access to the system. For example, the tester is also given accounts.
Black-Box Testing
The first thing to do when black-box testing is to map the application. This means visiting the URL of the application, walking through all the pages accessible within the user context, and make note of all input vectors that could potentially be used to retrieve data from the server file system. This could be any parameters that contain the name of the file or directory.
Once all the instances have been identified, it is a matter of testing/fuzzing these instances with common traversal payloads. Some sample directory traversal payloads include:
../../../../etc/passwd
../../../etc/passwd
../../.htaccess
\..\WINDOWS\win.ini
\..\..\WINDOWS\win.ini
…
The idea is that you submit the payload and analyze how the app responds. If it responds in a way that it is not supposed to (i.e. outputting the contents of a file you requested, or generating a verbose error or a different status code), then it is a matter of fine tuning your payload until you can successfully exploit the vulnerability.
This can be achieved manually however, it does become tedious and you may miss stuff. Usually for this vulnerability, you would use the help of a web application vulnerability scanner (WAVS) to automate the process for us.
White-Box Testing
The first thing to do is identify all instances in the application where user-supplied input is being passed to file APIs or as parameters to the OS. This can be done in many ways. The first way to do this is a mixture of black and white box testing.
This means that we first map it and identify instances where the application could be potentially interacting with the file system. Then, we focus only on reviewing the code that is responsible for these parameters/instances instead of reviewing all the code.
The second option is to grep on certain functions in the code that are known to include and evaluate files on the server and review if they take user supplied input. If they do, check if any validation is in place to ensure malicious input does not go through.
The third option is if you have local access to the application. You can use a tool to monitor all filesystem activity on the server then test each page of the application by inserting a single unique string in each parameter at a time and then filter the file system monitoring tool to identify all file system events that contain that specific unique string. If you see any events, then for sure the application is interacting with the filesystem and so you test the app/view the code to see if it is vulnerable.
Remember, that in any method, you always have to validate that the application is vulnerable by entering your payload in a running application.
Exploiting Directory Traversal
The most common way you will encounter is the “regular case” where there is no validation in the back end. With this, you could use the path traversal sequence (../) to traverse out of the current directory and try to access a world readable file like passwd or win.ini. Some example payloads are:
../../../../../../../../../etc/passwd
.\..\..\..\..\..\windows\win.ini
In other cases, you will encounter inadequate validation put in place by the developers. This would hinder your ability to exploit it, but does not make it impossible. The first way is developers stripping out all path traversal sequences (../). In that case, you could try to put the absolute path of the file and see if that works. For example:
/etc/passwd
If that does not work, you could try using recursive traversal sequences. This will only work if traversal sequences are stripped non-recursively. If the application is non-recursively stripping the sequences, it will remove the characters only once. An example payload is:
….//….//….//etc/passwd
Another thing to try is URL encoding the payload or double encoding the payload. You can even use non standard encoding to pass defense mechanisms:

Another case is the application requiring the parameter to start with a specific file path. For example, it must start with /var/www/images. In that case, you would exploit it by just keeping the path in the parameter and using a regular payload to view the file such as:
/var/www/images/../../../etc/passwd
Finally, some apps require the file to have a specific extension. In that case, you could use a null byte represented as %00 to tell the app to ignore anything after the null byte. This way, you could include the required file extension and use the null byte to ignore it - it does NOT work for all frameworks and languages. It requires the framework and the app to be able to process null bytes and ignore everything after it.
Web Application Vulnerability Scanners (WAVS)
Web App Vulnerability Scanners (WAVS) are automated tools that crawl the web app and look for vulnerabilities. Most scanners will have the ability to test for directory traversal and have built-in payload lists specific to this vulnerability. It’s highly recommended to use a scanner to test for this type of vulnerability since it is more efficient and more accurate than doing it manually.

Preventing Directory Traversal
The best way to prevent directory traversal is to avoid passing user-supplied input to file system APIs. In a majority of cases, this can all be implemented in the back end and you do not really need user input to access the file system.
However, if that is unavoidable, then you can use a combination of 2 layers of defense to prevent this attack. The first one is to validate user input by comparing it to an allow list of permitted values. If that is not possible, ensure that the input only contains alphanumeric characters.
Once that is done, the second layer is to use file system APIs to canonicalize the path and verify that it starts with the expected directory. If all your files are in /var/www/images, then the request for a file has to absolutely start with that path and nothing else.

Lab 1 - File Path Traversal (Simple Case)
This lab description tells us that there is a path traversal vulnerability in the display of product images and our end goal is displaying /etc/passwd.
As always in this series, it’s a good idea to get into the rhythm of mapping out the application before starting to fire potential exploits at it. To do this, simply browse around the application, see what you can click on, if you can log in, register an account, view the source, and map it out. After a short while, a site map gets generated by Burp Suite if we have it running whilst doing our mapping:

Right off the bat, nothing jumps out and screams “look at me!”. If we are looking for directory traversal vulnerabilities or just looking at web vulnerabilities in general, a great starting point is looking at any request that provides parameters. In Burp Suite, in the Proxy tab, there is the ability to quickly see if a request used a parameter by providing a tick mark:

Here, we can see that the product page includes a parameter title productId. It’s unlikely that this is vulnerable to directory traversal as it’s not getting a file, but it can’t hurt to try. Grabbing one of the existing requests and inputting it into Repeater and sending it off reveals the normal response we should get - a 200 OK response:

Now that we know the expected response is a 200 OK with the page for that particular product, we can try and do a test for directory traversal by providing ../../../ as the productId’s value.

And we get a 400 Bad Request error response. It may be possible this parameter is vulnerable, but is not vulnerable to directory traversal. This is what we expected as it wasn’t really grabbing any file, rather just performing what was likely a backend lookup for a matching productId to provide the appropriate page.
Knowing this, we can move attack vectors. Scrolling through the website, you should have noticed images being loaded for each product page and on the main page itself. Images are also a very important target to test for directory traversal as they are likely stored in an images folder somewhere.
Looking at the source code of the main page and inspecting the code for a specific image, we can see it grabs the image from the /image folder:

It seems more likely to be vulnerable. Using this, we can modify the request in Burp to navigate to the /image folder and see what happens:

Just navigating to /image tells us that it is missing a parameter called “filename”. With this information now enumerated, we can provide the parameter by adding “?filename=test” to the GET request and see what happens next:

Now, we get a different error telling us that no such file exists - a good indicator. Now, we can complete this and validate the URL we found in the source code by providing the same image - 21.jpg - and we should expect to see a JPG file in the response (at least the garbled output of it):

And we do. Now that we know the full URL path for getting images, we can try a simple traversal by simply asking it for the /etc/passwd using a couple of ../’s to get there:

It works and the /etc/passwd file is returned to us on the web page. This was the most basic of examples, but the idea was to get hands-on with what directory traversal was and how it can be exploited. Now, let’s start playing around with filters and restrictions to make it harder.

Lab 2 - Traversal Sequences Blocked with Absolute Path Bypass
This lab description tells us that there is a path traversal vulnerability in the display of product images and it blocks traversal sequences but treats the supplied filename as being relative to a default working directory.
After spawning the lab, we can navigate to the site and look around as a normal end user:

It appears to be a simple shopping site at first where users can buy products. After clicking around, browsing various links, looking at product pages, we can start to build out a site map in the background in Burp Suite. At the end, it should look similiar to the following:

Here, we can see all the pages it found, including ones we didn’t navigate to but were linked to in the source code. With directory traversal vulnerabilities, we are interested in URLs that contain parameters, particularly ones that seem to include or load a certain thing (i.e. loading images). From above, we can see something titled “image” that we can look at further in Repeater.
Once in Repeater, we can send the request as is (GET /image) and see what happens.

We get a 400 Bad Request response back with a helpful error message telling us that the “filename” parameter is missing. This helps us as we can now add the parameter manually with a random string value such as “test” and resend it.

This time, after sending a valid request, the web page returns the same 400 Bad Request error, but a different error message - “No such file”. This indicates that the request is valid, but that it could not find any file called “test” in the directory, likely being /var/www/images or something similiar.
To test this further, we can try providing an image we know exists on the server and it listed on a product page. In this case, 7.jpg was used:

This is what a normal request should look like if the specified file/image exists on the webpage or inside the specified images directory. With this information, we can try using the same directory traversal as before, to grab the/etc/passwd file.

Unfortunately, this does not work and we get the same error - No such file. It may be that we are not far enough back in the filesystem to find /etc/passwd so we can try adding a ton more just to check:

Again, no luck. As we’re not getting any sort of error with the “../”, one of the options we have for directory traversal is specifying the absolute path as opposed to the relative path. For the /etc/passwd, the absolute path would be exactly that - /etc/passwd:

And it works!
What’s likely happening in this case is that the server may be removing any sort of directory traversal sequence such as the double dot (..), but still allows for absolute file paths since the double dot is not needed, although this is just a theory. From there, we can see on the main web page that we successfully complete the lab.
A short note to take into consideration is that when we usually think about directory traversal, we tend to immediately think of these sequences such as “../”. However, that is not the only way to find a vulnerability. Sometimes the back end may block these sequences or relative paths, but may forget to blacklist/disallow absolute paths, allowing directory traversal.
Lab 3 - Traversal Sequences Stripped Non-Recursively
First, as with the pervious labs, we simply navigate to the website, click around, map it out and see what the landscape looks like. After a short while, we should see the following in Burp Suite:

We see the same thing again. As before, we can check the image page and use the filename parameter to grab an image from the web server to display for the certain product page. Below is an example request for the file named “7.jpg”:

As you can see, the normal response is a 200 OK and the contents of the file get displayed in this garbled output of the JPG image itself. Trying the long string of traversal sequences as before, we can try and access the /etc/passwd once more:

No such luck. What happens if we try and use absolute paths instead of relative paths?

Again, no luck and we get the “No such file” error. It seems that the back end server is sanitizing our input and removing any directory traversal sequences we try to input to it.
What’s likely happening is that the server is taking the string “../../../etc/passwd”, searching that string for any instance of the “../”, removing them from the string and continuing to process the request and return the file.
However, this is a vulnerability in and of itself. Once stripped of these sequences, a good web app should then do another check to see if the modified string contains any remaining sequences.
In the back end, there is likely some sort of PHP code that uses regular expressions to check for directory traversal sequences like this, but the problem is that it is only being run and checked once. This works in theory, but in practice, an attacker can get around this by putting two of each in the string such as:
….//….//….//….//….//….//etc//passwd
What happens now is that if the web application is badly programmed to only perform this check and sanitization once and not recursively (i.e. over and over again), then it will first check the input above for any instance of “../” and remove it. However, it will only remove them once, thereby leaving the following payload:
../../../../../../etc/passwd
This, in theory, should return and bypass the sanitization check and grab the /etc/passwd file. We can check this by modifying our string to this payload and checking the response:

It works and we effectively bypass the sanitization check due to a lack of recursiveness. Going back to the main page, we see we completed the lab.

This is just one of the checks we can perform if the web app is performing sanitization on directory traversal sequences - is the web app sanitizing the sequences correctly? Does it perform one check, then re-input the modified string back into the check over and over recursively, until no sequences can be found or does it do it just once?
Lab 4 - Traversal Sequences Stripped with Superfluous URL-decode
Common practice as always - start up Burp Suite, map the application, click links, browse around, get used to the normal functionality of the site. After a while, we generate a sitemap in Burp Suite and can begin poking around from there:

As before, we are interested in the image page with the filename parameter and can test it out by providing a known image that gets loaded - 7.jpg:

From the above, we can see standard output when we provide a file that exists. Knowing this, we can test a few directory traversal sequences, but none of them work. Below is the sequence used in Lab 3 where we bypass a single sanitization check. However, this time it does not work.

Why? Well, like what is happening now is that the directory traversal sequence checks are being run recursively, so no matter how many dots and slashes we put, it likely gets filtered out until the inputted string becomes safe and sanitized.
However, what about if we encode the payload/string? A simple check to make is by URL encoding the payload. In Burp Suite, we can navigate to the Decoder tab and on the top pane, input the string we want to encode (in this case, it is the “../” sequence). On the right, we then check that we want to encode it as URL encoding and the output gets provided in the bottom pane:

It might be hard to see, but the encoded output comes out as “%2e%2e%2f” where the %2e represents the full stop/dot (.) and the %2f represents the forward slash (/). From here, we can try and input a couple of these encoding traversal sequences with the single slash also being encoded between /etc and passwd just to make sure:

Unfortunately, it does not work.
What’s likely happening at the back end is the server is receiving this pre-URL encoded string (it knows what to do with URL-encoded strings), it decodes them so it ends up with the raw plaintext version (../../../../etc/passwd), likely looks at it for directory traversal sequences, sanitizes it or simply rejects it from executing.
However, there is a potential bypass in the form of double URL encoding. Using Decoder, we can do this by first submitting the cleartext (../), then copy and pasting the URL encoded output and URL encoding it again to end up with the final form being %25%32%65%25%32%65%25%32%66 (I know, it’s hard to read).

So what’s happening here is it is taking that first URL encoded string (%2e%2e%2f) and URL encoding each character again. For example, URL encoding a % sign, you end up with %25 and so on. Submitting this large double URL encoded payload works and we successfully print out the contents of /etc/passwd:

But, why does it work? Well, pretend we are the server and we receive the double URL encoded string as follows:
%25%32%65%25%32%65%25%32%66etc%25%32%66passwd
The server will first URL decode the string (servers are stupid, so may not realize it is double URL encoded, silly computer).With this, after decoding the string, it gets a single URL encoded string being:
%2e%2e%2fetc%2fpasswd
It then likely scans it for any blacklist sequences (i.e. ../). If any are found, it may sanitize them clean or refuse to process the request further. In this case, there are no sequences so the server assumes it is safe to forward on.
Normally, it would be safe as most apps only URL decode once. What happens if the server passes the single URL decoded string to the application/module that processes it? If that module has URL decoding functionality, it will run a URL decode itself until it gets what it believes to be a cleartext string. In this case, that would be:
../etc/passwd (shortened for clarity sake)
Uh oh! We have a problem. We’ve already bypasses the security check. The module takes that string, not running any security checks and our plaintext string with directory traversal sequences gets executed.
The below image clarifies this double URL encoding using the Burp Suite Inspector tool. As you can see the bottom part is the cleartext payload and the top part is the double URL encoded payload:

There is another, less convoluted way of doing this, through the Inspector tool itself. With this, we can input our cleartext payload and URL encode it once:

Hmmm….. looks different doesn’t it? The forward slash has been URL encoded - it has now become %2f. This is because the forward slash is declared as a reserved character. When using a URL in the bar, forward slashes are often used to clarify the path to the web server (i.e. google.com/my-account/settings). The dots are not URL encoded as they are not considered reserved characters.
In the previous example, every character in the string was encoded, regardless of their important/reservation status hence the difference.
If we do a second URL encoding on this, we produce the following:

As before, the forward slash is encoded as %2f. However, it is then encoded again. When performing the second encoding, the “2f” is kept the same as they are not reserved characters. However, the % sign is considered a special reserved characters so it gets encoded again as %25 - instead of %2f, we get %252f.
From there, the same steps happen as mentioned above. To clarify, this payload also works as can be seen below.

And this completes the lab!

Lab 5 - Validation of Start of Path
Common practice as always and after a while, we generate a sitemap in Burp Suite and can begin poking around from there:
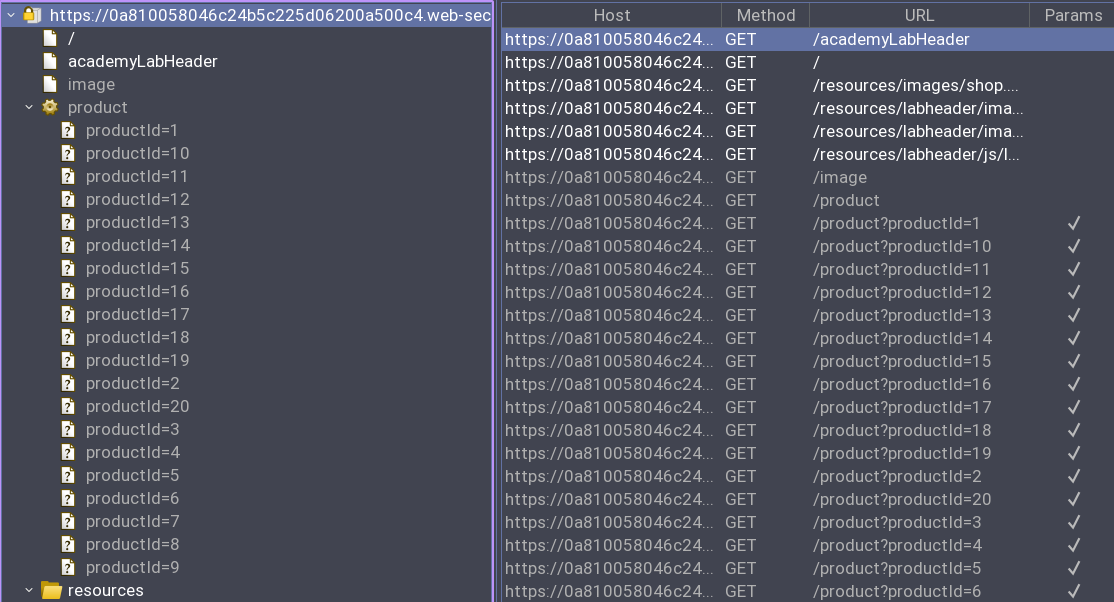
Once again, the same page seems to come back to haunt us. From here, we see the image page as usual, but let’s try a different approach this time. Navigating to one of the products page, we can see the image that we keep manipulating the request for.
If we view the source code of the page and check the image, we can see where it is loaded from. For this lab, it states the image is loaded from /image with the parameter ?filename with the path being /var/www/images/20.jpg

What happens if we navigate to that specified URL?

We can see the image loads successfully and we can see the URL includes the /var/www/images/20.jpg link to load the image from that folder. From here, we can generate a new request in Burp Repeater and send it to see what the output looks like in Repeater - the same as always, we get a 200 OK response and the image loads:

From here, we can try what we did in a previous lab by changing the value of the JPG file loaded to a number that likely doesn’t exist and see what error we can produce:

The famous error “No such file” appears. This lab is slightly different in the loading image approach as it includes what appears to be the full absolute path to the JPG file it wants to load. With this in mind, what happens if we simply replace the entire filename value with a directory traversal?

Interesting, we get a different error message, stating that the filename parameter was not specified. What’s likely happening here is that the server on the backend is checking that the /var/www/images directory appears in the filename parameter before performing any kind of processing or sanitization. If the /var/www/images is not specified, it does not see the filename parameter as successfully being sent.
With this in mind, what happens if we simply provide /var/www/images/ as the payload without specifying a JPG to grab?

We get the “No such file” error once again.. Just to confirm this theory about having to have a certain path in the parameter for the server to understand, we can try providing the absolute path for /etc/passwd to make sure it’s also filtering this out:

And we get the expected error - we are narrowing down our choices. One of the things to try if we think the server requires a certain path in the parameter is to simply add on to the end of the path. First, we can try specifying the /var/www/images directory at the start, which from above we can determine is a valid request but no file gets returned.
From there, we can try appending a directory traversal sequence to the end to try and tell the server to go up 3 directories and access the /etc/passwd file instead:

And it works. As a side note, this is a simple bypass and as you can notice, no encoding or double encoding was required here, but in a real application, you may have to combine these techniques in order to successfully bypass the server-side filters and sanitization checks.
As proof it worked, when you navigate to the home page, the congratulatory banner drops, indicating a completed lab.


Lab 6 - Validation of File Extension with Null Byte Bypass
Common practice as always and after a while, we generate a sitemap in Burp Suite and can begin poking around from there. As with the previous labs, the website looks the same:

In the previous lab, we looked at the URL in the browser by inspecting the source code. Doing the same here reveals that the /image page is back with the filename parameter and, in this case, the image titled “6.jpg”.

As with before, we can craft a request in Repeater and send it forward to identify what a normal response looks like:

Trying to modify the image requested with a large number that likely won’t exist returns the same error we’ve seen before - “No such file”:

If we try and perform a standard directory traversal with no filtering, we get the same error:

From here and by doing other methods performed, it seems that nothing works. With this lab, it’s using validation on the file extension or file type. It won’t return any results unless an image extension is used. Trying this with /etc/passwd.jpg, we get the same error as the file is not passwd.jpg, but rather just “passwd”.

A null byte is used to represent the end of a string in various languages. Most likely what is happening is we have the file name and the application takes that information and adds ".jpg" to the end to get "20.jpg" for example. In old PHP versions, one way to bypass this is to do "%00" - null byte.
The application will add a .jpg, but the null byte will kill that and end up with "/etc/passwd" again for example. The null byte essentially comments out the rest of the string. The server sees the request - ../../../../etc/passwd%00jpg - and thinks it is a legit request as it ends in JPG. With the null byte, it passes the initial verification, but the server then uses the string as part of a file read API.
First, the request hits the backend language and there will be no issues with the null byte. However, when forwarded to the operating system, it will assume the string is terminating after /etc/passwd because of the null byte - i.e. ignoring the .jpg extension.
Using Burp Inspector, we can enter the value we want to decode as /etc/passwd%00.jpg and see the decoded version becomes “\0”:

Knowing this, we can try sending the payload the server and observe the response. In this case, the null byte successfully bypasses the verification check, gets passed to the filesystem API where the null byte stops the string from being read any further than /etc/passwd and so we get the contents of passwd:
